Essential for life, fatty acids are crucial in energy metabolism, cell and membrane structure, and physiological regulation to all organisms, including Drosophila [Stanley-Samuelson, et al. 1988]. The fatty acid compositions of all insect orders are fairly similar, in a qualitative way. Biochemical profiles include about eight components with chain lengths of 12 to 18 carbons, most of these saturated and monounsaturated fatty acids (MUFAs) plus two polyunsaturated fatty acids (PUFAs) - Linoleic acid (LA, l8:2n-6) and а-linolenic acid (ALA,18:3n-3 ) [Stanley-Samuelson, et al. 1988]. The lipids of aquatic insects and some Antarctic beetles are abundant in long chain PUFAs with a chain length of 20 or 22 carbons. Certain C20 and C22 PUFAs play important regulatory roles in reproductive biology of some insect species. For example, arachidonic acid (AA, 20:4n-6) or certain structurally related C20 and C22 PUFAs are essential nutrients for several mosquito species [Stanley-Samuelson, et al. 1988], which may be reflective of the mosquito diet compared to that of fruit flies.
------------------
Reference
D.W. Stanley-Samuelson, R. A. Jurenka, C. Cripps. Fatty acids in insects: Composition, metabolism,and biological significance. Archives of Insect Biochemistry and Physiology. 9 (1988): l -33.
Thursday, July 15, 2010
Monday, July 12, 2010
ISMB 2010
Throughout the ISMB (Intelligent Systems for Molecular Biology) conference, I will add some notes and observations. Check for updates.
ISCB Overton Prize Lecture - Steven Brenner, Univ. of California, Berkeley (USA). Ultraconserved nonsense - Gene regulation by splicing and RNA surveillance. A nonsense mutation leads to a stop codon and a dominant negative mutant. NMD = nonssense-mediated mRNA decay, where mRNAs with a premature stop codon are recognized and the entire mRNA molecule is destroyed. For this reason, a 3'-UTR is rarely interrupted by an intron and why premature stop codons within the last exon can have much more dramatic or severe phenotypic consequences compared to premature stops further upstream.
Exon junction complexes (EJC) retain information on exon-exon joins. The EJCs are needed for transport from the nucleus and to mark the last exon (where the termination codon should be located). If the termination codon is greater than 50 nt upstream of the EJC, the rule of thumb states that the RNA is degraded.
So, why are so many genes transcribed with "poison" exons (those that produce a premature stop codon)? The tissue-specific splicing factors that produce the mRNA with premature stop functionally act as a transcriptional repressor via NMD.
In gene SRp55 (encoding a splicing factor) the poison cassette exon is 100% identical over more than 200 nt between human and mouse. Why so conserved? It does not encode protein, nor has a conserved RNA folding structure, no over-representation of known binding sites, no repetitive elements, no similarity elsewhere in the genome (except in retropseudogenes). The answer appears to lie in regulation of gene expression.
This mode of gene regulation appears ancient and repeated often. Possible role for ultraconserved region proposed.
- - - - - - - - - - - - - - - - - - - - - - - - - - - -
Ross Curtis, Carnegie Mellon Univ., Pittsburgh, PA (USA)
GenAMap: An integrated and analytic visualization software platform for structured GWAS and eQTL analysis. Association with a genetic network and SNP-based perturbation of a network. Structured association mapping:
Advantages: greater power to detect weak association signals, fewer false positives, joint association to multiple correlated phenotypes.
Disadvantages: computatinally intensive algorithm, specialized software.
Build and explore a genetic-phenotype network while looking at the association data. They are looking for beta users - contact the Sailing Lab, rcurtis@cs.cmu.edu.
- - - - - - - - - - - - - - - - - - - - - - - - - - - -
Enoch Huang, Pfizer
Computational Biology at Pfizer. The two main decision points in drug research and development: Target selection and compound selection.
- - - - - - - - - - - - - - - - - - - - - - - - - - - -
Charles Vaske,
Inference of specific-specific pathway activities from multi-dimensional cancer genomics data using PARADIGM. They treat the pathway as a single genetic unit. Calculate the log-likelihood ratio of three possible states of an entity: up, same, down. This is the basis of their "integrated pathway activities."
- - - - - - - - - - - - - - - - - - - - - - - - - - - -
Joel Dudley, Stanford Univ. (USA)
The robustness of disease signatures across tissues and experiments. How well do different experiments agree by correlation?
- same disease (D+) / same tissue (T+)
- same disease (D+) / different tissue (T-)
- different disease (D-) / same tissue (T+)
- different disease (D-) / different tissue (T-)
See Dudley, et al (2009) Disease signatures are robust across tissues and experiments. Molec. Sys. Biol. 5:307.
Now, considering global markers of disease and molecular systems of disease.
This short talk seemed to be mostly a rehash of the papers they've published and next to nothing on the last sentence above.
- - - - - - - - - - - - - - - - - - - - - - - - - - - -
Rune Linding,
Comparative Network analysis of complex diseases. Tyrosine kinases with less (vs. greater) specificity at site of phosphorylation are more likely to have an oncogenic effect when that gene is altered. This makes sense because the lower specificity will have a greater effect on the interaction network (kinase and substrates).
60-80% of cellular kinase specificity is determined by network context.
Evolutionarily conserved phosphorylation networks link multiple diseases.
Less specific kinases tend to be causally linked to cancer.
- - - - - - - - - - - - - - - - - - - - - - - - - - - -
Susan Lindquist, Whitehead Institute for Biomedical Research, Massachusetts Institute of Technology, Howard Hughes Medical Institute, Cambridge, MA (USA)
Protein folding and environmental stress REDRAW the relationship between genotype and phenotype. How do organisms stay the same? How do they change (rapidly, in some cases)?
Consider that Jean-Bapiste Lamarck and Conrad Waddington were not so crazy after all. They proposed that inheritance could occur via environmentally acquired traits.
She pointed out that a protein must fold ina very harsh, populated, complex environment. She demonstrated this with an image from David Goodsell. An example of his work is here. The concentration of protein in a cell is about the same as in a packed crystal.
Hsp90 - very abundant (~2% of protein)
- acts as a buffer of protein folding homeostasis
- has specialized clients: at later stages of folding, many of these clients are signal transducers whose folding is only completed when the signal comes in; these are proteins in meta-stable states
Drosophila Hsp90 mutants at half activity of wildtype show >100 phenotypes, pleiotropic, depending on the genetic background of the strain used. A similar result was noted for Arabidopsis thaliana.
Hsp90 acts a capacitor for some variation, allowing organisms to accumulate lots of genetic variation which is released when a stressor is applied.
Hsp90 also acts as a potentiator for other variation.
- in mammals, Hsp90 complexes with inactive hormone receptors, with inactive oncogenic kinases
She then described work with gal-induced v-Src. v-Src lacks the auto-inhibitory function found in c-Src. The Hsp90 down mutant lost all v-Src-induced phosphorylation, while c-Src-induced phosphorylation showed very little to no changes when Hsp90 was downregulated. Hsp90 stabilizes v-Src and gets it to the membrane, leaving it in place and in an active state.
She then went on to tell the story of Candida albicans and fluconazole resistance. Fluconazole resistance come about quite readily and thus is a serious clinical issue. So, reduce the Hsp90-specific buffering capacity and this leads to the observation of no fluconazole resistance. The buffer is the extra capacity of Hsp90 to fold proteins for normal activity. It is this buffering capacity that they knock down with treatment of a small molecule. In other words, the C. albicans are no longer primed to tolerate or adapt to the stress.
Hsp90 genotypes and phenotypes
- transforms adaptive value of large amounts of standing variation.
- affects polymorphisms throughout the genome, even non-coding (Hsp90 can assist folding of a 3'-UTR-binding protein that recognizes a structure of an mRNA with a variant base), in a combinatorial way.
- simple environmental stresses exert similar effects.
- has likely sculpted the standing variation that exists today in yeast genomes.
- matters to human health in many ways.
It was especially with regards to this last point that I wonder what her thoughts are on the stress-induced changes after a change in diet, say from a high-fat meal. This could alter the population of gut microbiome which could then exert a given amount of stress on cells lining the intestine. If I learn anything, I'll share.
- - - - - - - - - - - - - - - - - - - - - - - - - - - -
Svante Pääbo, Max Planck Institute for Evolutionary Anthropology, Leipzig (Germany).
So, what next? They now look at other homids. Denisova cave in Siberia. A bone fragment. Regarding mitochondria DNA (mtDNA), there are about 375 differences, on avg. between Denisova and human, with about 200 between human and Neandertal. That puts the Denisova branch about 1 mya, with Neandertal about 0.5 mya. This is based on the mtDNA sequences.
Lots more to consider.
- - - - - - - - - - - - - - - - - - - - - - - - - - - -
Chris Sander, Memorial Sloan Kettering Cancer Center, New York, NY (USA)
Systems biology of cancer - Diversity & simplicity - Integrated molecular profiling and clinical implications and new algorithms for perturbation cell biology.
There were two main parts to his talk: Cancer genomics and Perturbation cell biology.
Cancer genomics. Map alterations from 200 glioblastoma (GBM) samples. Use a GBM pathway that was published in 2007 in Genes & Development. For GBM there is no single molecular cause, but there is a common oncogenic program when you look at modules. For example, there are altered RTK/RAS/PI-3K signals in 85% of cases, altered p53 signaling in 86% of cases, and altered RB signals in 77% of cases. The challenge: use this information for network pharmacology and personalized therapy.
He gave two examples of taking on this challenge with prostate and ovarian cancers. With respect to prostate cancer and altered network signals, for RB 74% of metastatic cases and 34% of primary cases show alterations, for PI-3K 100% of met and 42% of 1o show alterations, and for RAS/RAF 90% of met and 43% of 1o show alterations. He showed data from changes in DNA copy number, many times CNV data were is data of choice.
Ovarian cancer. How many patients have damaged homologous repair mechanisms in ovarian cancer? This is one sub-project in the grander Cancer Genome Atlas. BRCA1 is inactivated in 21% of cases.
1. germline or somatic mutation
2. epigenetic silencing
3. homozygous deletion
47% of cases have at least one altered HR gene. Thus, drug trials with PARP inhibitors are under consideration. HR genes include BRCA1, BRCA2, PTEN, EMSY, ATM, ATR, RAD51C and FA genes (e.g., FANCA, FANCD2).
He then gave a quick overview of cbio.mskcc.org/cancergenomics
Perturbation cell biology. Form and consider a network module with input -> network -> output. When we don’t know the input, then we are talking about control. When we don’t know the network and its (inter)relationships, we are talking about interpretation. When we don’t know the output, we are talking about prediction. All of this is with an eye toward therapy.
He refered to published work. But, the question is, does it scale? Not to larger systems.
Use statistical physics to generate a series of probability distributions for all possible pairs Wij interacting over good solutions. Then, draw the network model. This is in place of going straight to all possible networks via Monte Carlo descent. Then, use this model to predict the effects of drug and genetic perturbations s in cancer.
- - - - - - - - - - - - - - - - - - - - - - - - - - - -
ISCB Overton Prize Lecture - Steven Brenner, Univ. of California, Berkeley (USA). Ultraconserved nonsense - Gene regulation by splicing and RNA surveillance. A nonsense mutation leads to a stop codon and a dominant negative mutant. NMD = nonssense-mediated mRNA decay, where mRNAs with a premature stop codon are recognized and the entire mRNA molecule is destroyed. For this reason, a 3'-UTR is rarely interrupted by an intron and why premature stop codons within the last exon can have much more dramatic or severe phenotypic consequences compared to premature stops further upstream.
Exon junction complexes (EJC) retain information on exon-exon joins. The EJCs are needed for transport from the nucleus and to mark the last exon (where the termination codon should be located). If the termination codon is greater than 50 nt upstream of the EJC, the rule of thumb states that the RNA is degraded.
So, why are so many genes transcribed with "poison" exons (those that produce a premature stop codon)? The tissue-specific splicing factors that produce the mRNA with premature stop functionally act as a transcriptional repressor via NMD.
In gene SRp55 (encoding a splicing factor) the poison cassette exon is 100% identical over more than 200 nt between human and mouse. Why so conserved? It does not encode protein, nor has a conserved RNA folding structure, no over-representation of known binding sites, no repetitive elements, no similarity elsewhere in the genome (except in retropseudogenes). The answer appears to lie in regulation of gene expression.
This mode of gene regulation appears ancient and repeated often. Possible role for ultraconserved region proposed.
- - - - - - - - - - - - - - - - - - - - - - - - - - - -
Ross Curtis, Carnegie Mellon Univ., Pittsburgh, PA (USA)
GenAMap: An integrated and analytic visualization software platform for structured GWAS and eQTL analysis. Association with a genetic network and SNP-based perturbation of a network. Structured association mapping:
Advantages: greater power to detect weak association signals, fewer false positives, joint association to multiple correlated phenotypes.
Disadvantages: computatinally intensive algorithm, specialized software.
Build and explore a genetic-phenotype network while looking at the association data. They are looking for beta users - contact the Sailing Lab, rcurtis@cs.cmu.edu.
- - - - - - - - - - - - - - - - - - - - - - - - - - - -
Enoch Huang, Pfizer
Computational Biology at Pfizer. The two main decision points in drug research and development: Target selection and compound selection.
- - - - - - - - - - - - - - - - - - - - - - - - - - - -
Charles Vaske,
Inference of specific-specific pathway activities from multi-dimensional cancer genomics data using PARADIGM. They treat the pathway as a single genetic unit. Calculate the log-likelihood ratio of three possible states of an entity: up, same, down. This is the basis of their "integrated pathway activities."
- - - - - - - - - - - - - - - - - - - - - - - - - - - -
Joel Dudley, Stanford Univ. (USA)
The robustness of disease signatures across tissues and experiments. How well do different experiments agree by correlation?
- same disease (D+) / same tissue (T+)
- same disease (D+) / different tissue (T-)
- different disease (D-) / same tissue (T+)
- different disease (D-) / different tissue (T-)
See Dudley, et al (2009) Disease signatures are robust across tissues and experiments. Molec. Sys. Biol. 5:307.
Now, considering global markers of disease and molecular systems of disease.
This short talk seemed to be mostly a rehash of the papers they've published and next to nothing on the last sentence above.
- - - - - - - - - - - - - - - - - - - - - - - - - - - -
Rune Linding,
Comparative Network analysis of complex diseases. Tyrosine kinases with less (vs. greater) specificity at site of phosphorylation are more likely to have an oncogenic effect when that gene is altered. This makes sense because the lower specificity will have a greater effect on the interaction network (kinase and substrates).
60-80% of cellular kinase specificity is determined by network context.
Evolutionarily conserved phosphorylation networks link multiple diseases.
Less specific kinases tend to be causally linked to cancer.
- - - - - - - - - - - - - - - - - - - - - - - - - - - -
Susan Lindquist, Whitehead Institute for Biomedical Research, Massachusetts Institute of Technology, Howard Hughes Medical Institute, Cambridge, MA (USA)
Protein folding and environmental stress REDRAW the relationship between genotype and phenotype. How do organisms stay the same? How do they change (rapidly, in some cases)?
Consider that Jean-Bapiste Lamarck and Conrad Waddington were not so crazy after all. They proposed that inheritance could occur via environmentally acquired traits.
She pointed out that a protein must fold ina very harsh, populated, complex environment. She demonstrated this with an image from David Goodsell. An example of his work is here. The concentration of protein in a cell is about the same as in a packed crystal.
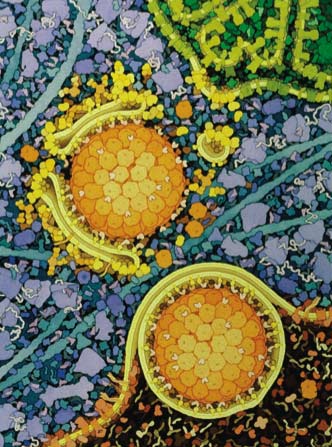{kind=link}
Hsp90 - very abundant (~2% of protein)
- acts as a buffer of protein folding homeostasis
- has specialized clients: at later stages of folding, many of these clients are signal transducers whose folding is only completed when the signal comes in; these are proteins in meta-stable states
Drosophila Hsp90 mutants at half activity of wildtype show >100 phenotypes, pleiotropic, depending on the genetic background of the strain used. A similar result was noted for Arabidopsis thaliana.
Hsp90 acts a capacitor for some variation, allowing organisms to accumulate lots of genetic variation which is released when a stressor is applied.
Hsp90 also acts as a potentiator for other variation.
- in mammals, Hsp90 complexes with inactive hormone receptors, with inactive oncogenic kinases
She then described work with gal-induced v-Src. v-Src lacks the auto-inhibitory function found in c-Src. The Hsp90 down mutant lost all v-Src-induced phosphorylation, while c-Src-induced phosphorylation showed very little to no changes when Hsp90 was downregulated. Hsp90 stabilizes v-Src and gets it to the membrane, leaving it in place and in an active state.
She then went on to tell the story of Candida albicans and fluconazole resistance. Fluconazole resistance come about quite readily and thus is a serious clinical issue. So, reduce the Hsp90-specific buffering capacity and this leads to the observation of no fluconazole resistance. The buffer is the extra capacity of Hsp90 to fold proteins for normal activity. It is this buffering capacity that they knock down with treatment of a small molecule. In other words, the C. albicans are no longer primed to tolerate or adapt to the stress.
Hsp90 genotypes and phenotypes
- transforms adaptive value of large amounts of standing variation.
- affects polymorphisms throughout the genome, even non-coding (Hsp90 can assist folding of a 3'-UTR-binding protein that recognizes a structure of an mRNA with a variant base), in a combinatorial way.
- simple environmental stresses exert similar effects.
- has likely sculpted the standing variation that exists today in yeast genomes.
- matters to human health in many ways.
It was especially with regards to this last point that I wonder what her thoughts are on the stress-induced changes after a change in diet, say from a high-fat meal. This could alter the population of gut microbiome which could then exert a given amount of stress on cells lining the intestine. If I learn anything, I'll share.
- - - - - - - - - - - - - - - - - - - - - - - - - - - -
Svante Pääbo, Max Planck Institute for Evolutionary Anthropology, Leipzig (Germany).
Analyzing pleistocene hominid genomes. Human to human comparisons show differences of 1 per every 1000 bases; compared to chimp that 1 every 100. But this is not the best way to describe all we want to know about human lineage and human evolution.
He described the extraction of DNA for the first time from a mummy, a 2700-year old mummy from Egypt. The DNA is so highly fragmented that most of this work has been done with mitochondrial DNA.
Neandertal existed from 200,000 or 400,000 years ago to their extinction about 30,000 years ago, according to the fossil record. Two hypothesis: Replacement (all modern humans are equally distant from Neandertal) or Assimilation (some modern humans will closer to Neandertal (N) than other humans). The common ancestor of H. sapiens and N is ~0.6 mya. With second generation sequencing his group can now tackle the N nuclear genome in order address evolution questions.
A bone fragment from Vindija Cave, Croatia gave them their source material. Only ~3.5% of the sequence is primate. Most of the rest is bacterial and fungal from organisms that invaded the bone of the deceased individual. In the end, they have ~1.5x coverage with most of the reads coming approximately equally from three sources in Vindija.
Any position in N genome carries a risk of a bit less than 1% that the data are really from modern human (contamination). He talked about deamination of C to U, which is then read at T. This occurs mostly at fragment ends. They devised a manner to remove these ends. They aligned their N sequence fragments to both human and chimp in order to remove biases of a simple alignment to human.
Divergence to human reference genome shows 12.7%, translating to ~825,000 years ago. They looked at points fixed in the human, post-N lineage. There are 78 amino acid substitutions from about half of the N genome (thus the number will double), but is down to 50 because of very rare variants found from 1000 Genomes Project. Number is in flux.
Positive selection. ~10% of SNPs in human show that N has the derived allele. Did they see a depletion of derived alleles in N? THADA shows the most extreme variation from this - hence under selection. He showed Table 3 from their paper on the top 20 such selected regions. Humans have a 9-bp insertion in an intron of THADA. However, about 3-4% of Europeans have no 9-bp insertion and they are protected against type 2 diabetes.
RUNX2. Cleidocranial dysplasia. He mentioned the clavial, cranial frontal bulging and rib cage shape. So, differences in the RUNX2 may have to do with these skeletal differences between N and present day humans.
What does N have at SNPs that tag for Eurasia? For ten of twelve analyzed, N shows the non-African human allele. He compared N to Venter's genome (someone they believe to be a fully modern human). Some points showed a sharing of derived alleles. In the end, a series of comparisons indicate that ~90,000 years ago, humans met N and interbred. Thus, ~1-4% of H. sapiens DNA is derived from N.
Of those who have written email to Pääbo regarding their own ancestry and affiliation, 46 men claim to Neandertal and 3 women claim to be Neandertal. Furthermore, many more women claim to be married to a Neandertal than men claiming their spouse to be a Neandertal.
So, what next? They now look at other homids. Denisova cave in Siberia. A bone fragment. Regarding mitochondria DNA (mtDNA), there are about 375 differences, on avg. between Denisova and human, with about 200 between human and Neandertal. That puts the Denisova branch about 1 mya, with Neandertal about 0.5 mya. This is based on the mtDNA sequences.
Lots more to consider.
- - - - - - - - - - - - - - - - - - - - - - - - - - - -
Chris Sander, Memorial Sloan Kettering Cancer Center, New York, NY (USA)
Systems biology of cancer - Diversity & simplicity - Integrated molecular profiling and clinical implications and new algorithms for perturbation cell biology.
There were two main parts to his talk: Cancer genomics and Perturbation cell biology.
Cancer genomics. Map alterations from 200 glioblastoma (GBM) samples. Use a GBM pathway that was published in 2007 in Genes & Development. For GBM there is no single molecular cause, but there is a common oncogenic program when you look at modules. For example, there are altered RTK/RAS/PI-3K signals in 85% of cases, altered p53 signaling in 86% of cases, and altered RB signals in 77% of cases. The challenge: use this information for network pharmacology and personalized therapy.
He gave two examples of taking on this challenge with prostate and ovarian cancers. With respect to prostate cancer and altered network signals, for RB 74% of metastatic cases and 34% of primary cases show alterations, for PI-3K 100% of met and 42% of 1o show alterations, and for RAS/RAF 90% of met and 43% of 1o show alterations. He showed data from changes in DNA copy number, many times CNV data were is data of choice.
Ovarian cancer. How many patients have damaged homologous repair mechanisms in ovarian cancer? This is one sub-project in the grander Cancer Genome Atlas. BRCA1 is inactivated in 21% of cases.
1. germline or somatic mutation
2. epigenetic silencing
3. homozygous deletion
47% of cases have at least one altered HR gene. Thus, drug trials with PARP inhibitors are under consideration. HR genes include BRCA1, BRCA2, PTEN, EMSY, ATM, ATR, RAD51C and FA genes (e.g., FANCA, FANCD2).
He then gave a quick overview of cbio.mskcc.org/cancergenomics
Perturbation cell biology. Form and consider a network module with input -> network -> output. When we don’t know the input, then we are talking about control. When we don’t know the network and its (inter)relationships, we are talking about interpretation. When we don’t know the output, we are talking about prediction. All of this is with an eye toward therapy.
He refered to published work. But, the question is, does it scale? Not to larger systems.
Use statistical physics to generate a series of probability distributions for all possible pairs Wij interacting over good solutions. Then, draw the network model. This is in place of going straight to all possible networks via Monte Carlo descent. Then, use this model to predict the effects of drug and genetic perturbations s in cancer.
- - - - - - - - - - - - - - - - - - - - - - - - - - - -
Thursday, July 8, 2010
Olive oil and cancer
Could a diet where olive oil is the primary source of fat assist in delaying or preventing the onset of cancer? That's a tempting question and certainly a good one for nutrigenomics. As one might expect, the answer is both a yes and a no.
Yes. A recent study by Hirsch, Struhl, et al. used two isogenic cancer models to uncover the transcript profile and gene signature linking cancer with inflammatory and metabolic diseases. This group identified 345 genes whose expression signature is also involved in inflammation and metabolic diseases such as type 2 diabetes and cardiovascular disease. In fact, within these 345 genes are genes identified by GWAS (and other types of studies) for HDL-cholesterol (ABCA1 and GALNT2), obesity (NPC1), stroke (AIM1), and celiac disease (PTPN2, PTPRK, SCHIP1 and ZMIZ1), among others. Curiously, there is substantial sharing of genes between those upregulated in this cancer set and those that we identified as downregulated after acute intake of phenol-rich olive oil. Ten genes are shared. This is a 4.2-fold enrichment over what one would expect by chance given the size of the two gene sets. That sounds quite strong and the genes look mighty interesting:
ANXA3 - annexin A3
CXCL3 - chemokine (C-X-C motif) ligand 3
DUSP1 - dual specificity phosphatase 1
EREG - epiregulin
IER2 - immediate early response 2
IL1B - interleukin 1, beta
IL6 - interleukin 6 (interferon, beta 2)
JUNB - jun B proto-oncogene
SOCS3 - suppressor of cytokine signaling 3
SOD2 - superoxide dismutase 2, mitochondrial
These are some big players and so perhaps there is an olive oil-cancer prevention link.
However...
No. Because not everyone living in countries with heavy use of olive oil in the diet, countries such as Spain and Italy, adheres to a typical or Mediterranean diet, population data on cancer rates are not really an accurate way to assess that an olive oil-rich or Mediterranean diet lowers one's risk of cancer. Besides, cancer is too general a term - risk of specific types of cancer should be measured. For example, adherence to the traditional Mediterranean diet is associated with reduced risk of upper aerodigestive tract cancers and reduced risk of colorectal cancer has been observed in those who follow a diet higher in fruits/vegetables, lower in fat and more toward a Mediterranean diet.
The list of common cancer pathway genes is much greater than 10. Some 240 genes are upregulated and 105 are downregulated. Thus, while the 10 cancer pathway, olive oil-sensitive genes listed above are a highly interesting list, this is by no means sufficient to unequivocally state that a diet high in phenol-rich olive oil will prevent cancer.
Furthermore, many of the genes in this list of 10 are common to several important pathways. IL1B is a pro-inflammatory mediator and is also involved in the postprandial response of triglyderides. The floxed Socs3 gene in mouse gives an animal that is resistant to diet-induced obesity and this gene has been assigned to an insulin resistance inflammation network. One major point of our olive oil paper was the anti-inflammation nature of the response to the phenol-rich olive oil on gene expression in PBMCs. A recent paper essentially confirms this finding. Hence, the dual assignment of many genes to a cancer pathway and something else like inflammation is highly intriguing, but caution is, as always, warranted in condensing the complexities of metabolism, inflammation and cancer to a single kernel of dietary advice.
Yes. A recent study by Hirsch, Struhl, et al. used two isogenic cancer models to uncover the transcript profile and gene signature linking cancer with inflammatory and metabolic diseases. This group identified 345 genes whose expression signature is also involved in inflammation and metabolic diseases such as type 2 diabetes and cardiovascular disease. In fact, within these 345 genes are genes identified by GWAS (and other types of studies) for HDL-cholesterol (ABCA1 and GALNT2), obesity (NPC1), stroke (AIM1), and celiac disease (PTPN2, PTPRK, SCHIP1 and ZMIZ1), among others. Curiously, there is substantial sharing of genes between those upregulated in this cancer set and those that we identified as downregulated after acute intake of phenol-rich olive oil. Ten genes are shared. This is a 4.2-fold enrichment over what one would expect by chance given the size of the two gene sets. That sounds quite strong and the genes look mighty interesting:
ANXA3 - annexin A3
CXCL3 - chemokine (C-X-C motif) ligand 3
DUSP1 - dual specificity phosphatase 1
EREG - epiregulin
IER2 - immediate early response 2
IL1B - interleukin 1, beta
IL6 - interleukin 6 (interferon, beta 2)
JUNB - jun B proto-oncogene
SOCS3 - suppressor of cytokine signaling 3
SOD2 - superoxide dismutase 2, mitochondrial
These are some big players and so perhaps there is an olive oil-cancer prevention link.
However...
No. Because not everyone living in countries with heavy use of olive oil in the diet, countries such as Spain and Italy, adheres to a typical or Mediterranean diet, population data on cancer rates are not really an accurate way to assess that an olive oil-rich or Mediterranean diet lowers one's risk of cancer. Besides, cancer is too general a term - risk of specific types of cancer should be measured. For example, adherence to the traditional Mediterranean diet is associated with reduced risk of upper aerodigestive tract cancers and reduced risk of colorectal cancer has been observed in those who follow a diet higher in fruits/vegetables, lower in fat and more toward a Mediterranean diet.
The list of common cancer pathway genes is much greater than 10. Some 240 genes are upregulated and 105 are downregulated. Thus, while the 10 cancer pathway, olive oil-sensitive genes listed above are a highly interesting list, this is by no means sufficient to unequivocally state that a diet high in phenol-rich olive oil will prevent cancer.
Furthermore, many of the genes in this list of 10 are common to several important pathways. IL1B is a pro-inflammatory mediator and is also involved in the postprandial response of triglyderides. The floxed Socs3 gene in mouse gives an animal that is resistant to diet-induced obesity and this gene has been assigned to an insulin resistance inflammation network. One major point of our olive oil paper was the anti-inflammation nature of the response to the phenol-rich olive oil on gene expression in PBMCs. A recent paper essentially confirms this finding. Hence, the dual assignment of many genes to a cancer pathway and something else like inflammation is highly intriguing, but caution is, as always, warranted in condensing the complexities of metabolism, inflammation and cancer to a single kernel of dietary advice.
Tuesday, July 6, 2010
The genetics of O
Because this post is without data, it is certain to be disappointing to many. Nonetheless, investigation begins somewhere - a thought, an idea, a simple observation - and then may blossom into a complete project. Speaking of which, it would be a rather involved project to collect all published data and all of our unpublished observations regarding the genetics of O - overweight vs. obesity.
People who know our work, know that we have examined a lot of genotype-phenotype associations. While overweight/obesity is not our forte in the manner that blood lipids are, suffice to say that we have spent a fair amount of effort looking at genetic factors contributing to BMI. See, for example, this paper on APOA2 and this on PER2, relating chronobiology to obesity. Others have shown that variants in genes FTO, MC4R, LAMA2, SOX6, NEGR1, NPC1, TMEM18 and many others contribute to the risk of obesity.
Our basic observation is - we rarely see a genetic variant that associates with both overweight and obesity. Here, overweight in most populations is defined as a body mass index, or BMI, between 25 and 30 kg/m2 (where the kg reflects body weight in kilograms and m2 is the square of body height in meters). Obese is a BMI above 30. For some populations, these numbers are different due to different basic characteristics of body size.
So, what could this observation imply? My personal opinion is one centered on differences in the metabolic and biochemical (inflammation, adipocytokine) profiles of adipose tissue in the overweight vs. the obese individual. Thus, there may be an entirely different set of genetic variants, in combination with lifestyle choices of diet, exercise, lark-vs-owl chronotype and such, that contribute to the overweight situation compared to those that magnify the condition to one of obesity.
To me, this is an interesting topic and I would greatly appreciate your thoughts and comments.
People who know our work, know that we have examined a lot of genotype-phenotype associations. While overweight/obesity is not our forte in the manner that blood lipids are, suffice to say that we have spent a fair amount of effort looking at genetic factors contributing to BMI. See, for example, this paper on APOA2 and this on PER2, relating chronobiology to obesity. Others have shown that variants in genes FTO, MC4R, LAMA2, SOX6, NEGR1, NPC1, TMEM18 and many others contribute to the risk of obesity.
Our basic observation is - we rarely see a genetic variant that associates with both overweight and obesity. Here, overweight in most populations is defined as a body mass index, or BMI, between 25 and 30 kg/m2 (where the kg reflects body weight in kilograms and m2 is the square of body height in meters). Obese is a BMI above 30. For some populations, these numbers are different due to different basic characteristics of body size.
So, what could this observation imply? My personal opinion is one centered on differences in the metabolic and biochemical (inflammation, adipocytokine) profiles of adipose tissue in the overweight vs. the obese individual. Thus, there may be an entirely different set of genetic variants, in combination with lifestyle choices of diet, exercise, lark-vs-owl chronotype and such, that contribute to the overweight situation compared to those that magnify the condition to one of obesity.
To me, this is an interesting topic and I would greatly appreciate your thoughts and comments.
Subscribe to:
Posts (Atom)